
Oracle SQL - 단일행 함수 (Single Row Function)
Single-Row Function : 하나의 Row를 입력으로 받는 함수
- 숫자 함수
- 문자 함수
- 날짜 함수
- 변환 함수
- 기타 함수
Aggregation Function : 집합 함수
Analytic Function : 분석 함수
Regular Expression : 정규표현식 (Oracle 10g 이상)
문자열 함수
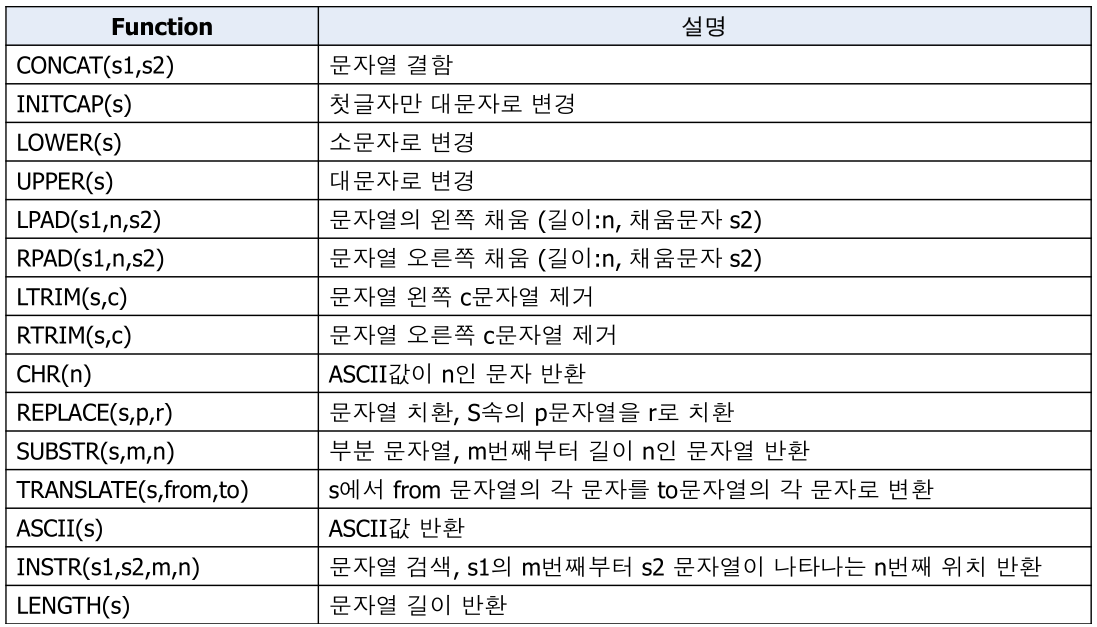
문자열 함수 사용 예

문자열 조작
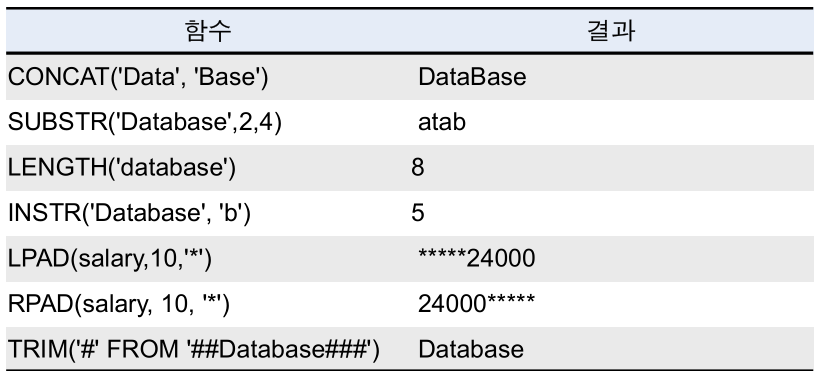
INITCAP(컬럼명)
- 영어의 첫 글자만 대문자로 출력하고 나머지는 소문차로 출력하는 함수
SELECT email, INITCAP(email), department_id
FROM employees
WHERE department_id = 100;LOWER(컬럼명) / UPPER(컬럼명)
- 문자열 값을 전부 소문자/대문자로 변경하는 함수
SELECT first_name, LOWER(first_name), UPPER(first_name)
FROM employees
WHERE department_id = 100;- 대소문자 구분 없이 문자열을 검색하고자 할 때 유용하게 사용
SUBSTR(컬럼명, 시작위치, 글자수)
- 주어진 문자열에서 특정 길이의 문자열을 구하는 함수
SELECT first_name, SUBSTR(first_name,1,3), SUBSTR(first_name,-3,2)
FROM employees
WHERE department_id = 100; - 시작 위치가 양수인 경우 왼쪽부터 검색하여 글자수만큼 추출
- 시작 위치가 음수인 경우 오른쪽 -> 왼쪽 검색을 한 후 글자수만큼 추출
예제
SELECT first_name , last_name, Concat(first_name, Concat(' ',Last_name)), -- 연결
Initcap(first_name||' '||last_name), -- 각 단어의 첫글자만 대문자
LOWER(first_name), -- 모두 소문자
UPPER(first_name), -- 모두 대문자
LPAD(first_name,10,'*'), -- 왼쪽 *로 채우기
RPAD(first_name,10,'*') -- 오른쪽 * 로 채우기
from employees;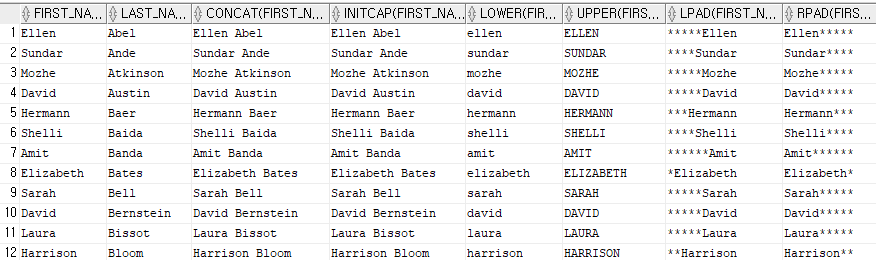
예제
SELECT LTRIM (' ORCLE '), -- 왼쪽 공백 제거
RTRIM(' ORCLE '), -- 오른쪽 공백 제거
TRIM('*' FROM '*********DATABASE*************'),
SUBSTR('ORACLE Database',8,4), -- 부분 문자열
SUBSTR('ORACLE Database',-8,8)
FROM employees;
숫자 함수

주요 숫자 함수
ROUND(숫자, 출력을 원하는 자리수)
- 주어진 숫자의 반올림을 하는 함수
SELECT ROUND(123.346, 2) "r2",
ROUND(123.456, 0) "r0",
ROUND(123.456, -1) "r-1"
FROM dual;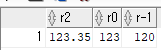
TRUNC(숫자, 출력을 원하는 자리수)
- 주어진 숫자의 버림을 하는 함수
SELECT TRUNC(123.346, 2) "r2",
TRUNC(123.456, 0) "r0",
TRUNC(123.456, -1) "r-1"
FROM dual;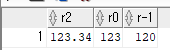
수치형 함수 예제
-- 수치형 단일행 함수
SELECT ABS (3.14), -- 절대값
CEIL (3.14), -- 소숫점 올림
FLOOR(3.14), -- 소수점 내림
MOD(7,3), -- 나머지
POWER (2,4), -- 제곱
ROUND(3.5), -- 소수점 반올림
ROUND(3.14159, 3), -- 소수점 3자리 까지 반올림 표현
TRUNC(3.5), -- 소수점 버리기
TRUNC(3.14159,3), -- 소수점 3자리까지 버림으로 표현
SIGN(-10) -- 부호 혹은 0
FROM dual;

Date 타입
Oracle의 Date Type
- century, year, month, day, hours, minutes, seconds 등을 포함한 내부 표현 (7bytes)
- Date Format에 따라 입/출력됨
- 기본 Date Format : 'RR/MM/DD' or 'DD-MON-RR'
- RR은 Y2K를 고려, 2자리 년도 표기 (00 ~ 49: 2000년대 / 50~99: 1900년대)
- 포맷 확인
SELECT value FROM nls_session_parameters WHERE parameter = 'NLS_DATE_FORMAT';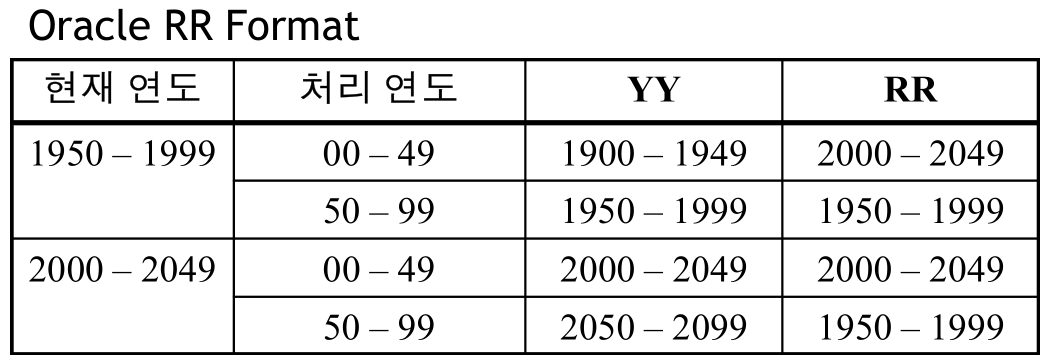
Date 함수

Date 함수 사용 예
주요 Date 함수
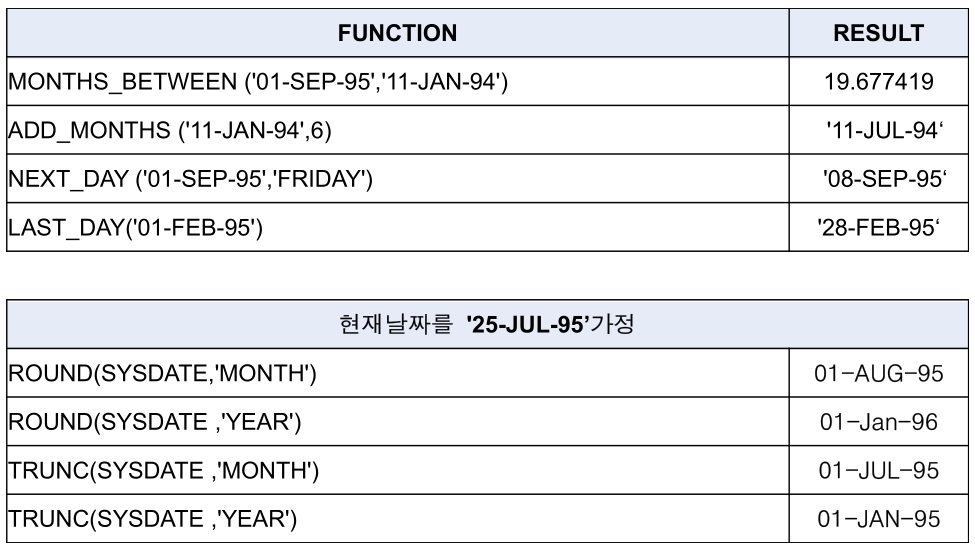
SYSDATE
- 현재 날짜와 시간을 출력해주는 함수
SELECT sysdate FROM dual;
SELECT sysdate FROM employees;
MONTH_BETWEEN(d1, d2)
d1 날짜와 d2 날짜 사이의 개월수를 출력하는 함수
SELECT MONTH_BETWEEN(sysdate, hire_date)
FROM employees
WHERE department_id = 110;SELECT SYSDATE,
ADD_MONTHS(sysdate,2), -- 2개월 후
LAST_DAY(SYSDATE), -- 이번달의 마지막 날
MONTHS_BETWEEN(SYSDATE,'99/12/31'), -- 1999년 12/31 이후 몇달이 지났는가?
NEXT_DAY(sysdate,7), -- 7일 후
ROUND(sysdate,'MONTH'),
ROUND(sysdate,'YEAR'),
TRUNC(sysdate,'MONTH'),
TRUNC(sysdate,'YEAR')
FROM dual;
변환 함수
- 묵시적 변환 : 변환 함수 없어도 어느 정도 자동으로 변환됨
- 자동으로 변환되지 않을 때는 명시적 변환 함수를 사용
Date 변환 포맷
예시는 American 포맷인 경우
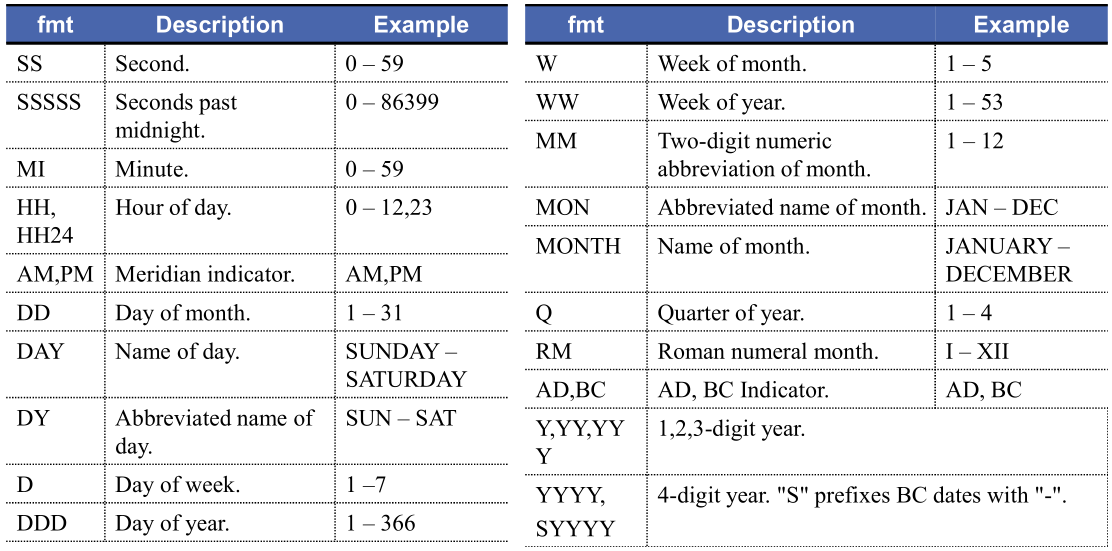

변환 연습 - TO_CHAR(날짜, '출력형식')
SELECT sysdate,
TO_CHAR(sysdate, 'YYYY-MM-DD HH24:MI:SS')
FROM dual;
숫자 변환 포맷
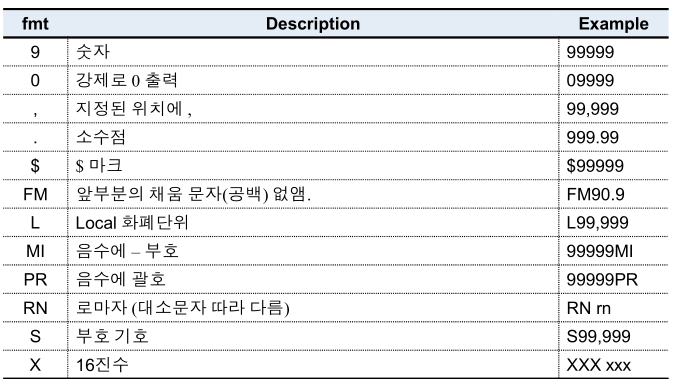
숫자 변환 포맷 연습
- TO_CHAR(숫자, '출력형식')
- 숫자형 -> 문자형으로 변환하기
SELECT first_name, to_char(salary*12, '$999,999.99') "SAL"
FROM employees
WHERE department_id = 110;
기타 함수
NULL 관련
- NVL(expr1, expr2) : expr1이 NULL이면 expr2, 아니면 expr1
- NVL2(expr1, expr2, expr3) : expr1이 NULL이면 expr3, 아니면 expr2
- NULLIF(expr1, expr2) : 두 식이 같으면 NULL, 아니면 expr1
- COALESCE(expr1, expr2, … exprN) : 첫 NOT NULL인 식 반환, 없으면 exprN
- 데이터 타입에 유의한다
EX)
SELECT ename, NVL(TO_CHAR(mgr), 'No Manager')
FROM emp;CASE
CASE {expr1} WHEN {expr2} THEN {expr3}
[WHEN {expr4} THEN {expr5}
...
ELSE {expr6}] - IF – THEN - ELSE와 비슷한 로직을 제공
- expr1이 expr2와 일치할 때 -> expr3
- expr1이 expr4와 일치할 때 -> expr5
- 만족하는 조건이 없으면 -> expr6
SELECT ename, job, sal, CASE job WHEN 'CLERK' THEN 1.10 * sal
WHEN 'MANAGER' THEN 1.15 * sal
WHEN 'PRESIDENT' THEN 1.20 * sal
ELSE sal END REVISED_SALARY
FROM emp;
DECODE
DECODE( {value}, {if1}, {then1}
[, {if2}, {then2}]
, {else} )SELECT ename, job, sal, DECODE(job, 'CLERK', 1.10 * sal,
'MANAGER', 1.15 * sal,
'PRESIDENT', 1.20 * sal,
sal) REVISED_SALARY
FROM emp;-- DML: SELECT
-----------------
-- SELECT ~ FROM
-- 전체 데이터의 모든 컬럼 조회
-- 컬럼의 출력순서는 정의에 따른다. 테이블 생성했을때 정의한 순서
SELECT * FROM employees;
SELECT * FROM departments;
-- 특정 컬럼만 선별하여 Projection
-- 사원의 이름, 입사일, 급여 출력
SELECT first_name, hire_date, salary FROM employees;
-- 산술연산 : 기본적인 산술 연산이 가능하다.
-- dual : 가상테이블.
-- 특정 테이블에 속한 데이터가 아닌
-- 오라클 시스템에서 값을 구한다.
SELECT 10*10*3.14159 FROM dual; -- 결과는 1개
SELECT 10*10*3.14159 FROM employees; -- 결과는 Table의 레코드 수 만큼.
-- 임플로이에서 퍼스트네임과 잡아이디를 불러와서 산술연산
SELECT first_name, job_id*12 From employees; -- 에러 발생 - jobid는 문자열이라 곱하기가 안됨.
desc employees;
SELECT first_name + ' ' + last_name FROM employees; -- ERROR 문자열끼리 합산은 불가하다.
-- 문자열 연결은 ||로 연결
SELECT first_name || ' ' || last_name FROM employees;
-- NULL
SELECT first_name, salary, salary*12 FROM employees;
SELECT first_name, salary, commission_pct FROM employees;
SELECT first_name, salary+salary * commission_pct FROM employees;
SELECT first_name, salary , commission_pct,salary+salary * commission_pct FROM employees; -- null이 포함된 산술식은 null
-- NVL
SELECT first_name, salary, commission_pct, salary+salary * NVL(commission_pct,0) FROM employees;
-- commision pct가 null이면 0으로 치환
-- Alias : 별칭
SELECT first_name || ' ' || last_name 이름, phone_number as 전화번호, salary "급 여" FROM employees;
-- 공백 여백이면 ""로 묶는다
--[예제] hr.employees 전체 튜플에 다음과 같이 Column Alias를 붙여 출력해 봅니다
-- 이름 : first_name last_name
-- 입사일: hire_date
-- 전화번호 : phone_number
-- 급여 : salary
-- 연봉 : salary * 12
SELECT first_name || ' ' || last_name 이름, hire_date 입사일, phone_number 전화번호, salary 급여, salary * 12 연봉 FROM employees;
-- 비교연산
-- 급여가 15000 이상인 사원의 목록
SELECT first_name, salary From employees Where salary>=15000;
-- 날짜도 대소 비교 가능
-- 입사일이 07/01/01 이후인 사원의 목록
SELECT First_name, hire_date From employees where hire_date>'07/01/01';
-- 이름이 lex인 사원이 이름, 급여, 입사일 출력
select first_name , salary, hire_date From employees where first_name = 'Lex';
-- 논리연산자
-- 급여가 14000 이하이거나 17000 이상인 사원의 목록
select first_name, salary FROM employees where salary<10000 or salary>17000;
-- 급여가 14000 이상, 17000 이하인 사원의 목록
select first_name, salary FROM employees where salary>=14000 and salary<=17000;
-- BETWEEN : 위 쿼리와 결과 동일
select first_name, salary FROM employees where salary BETWEEN 14000 and 17000;
-- NULL 체크
-- =NULL, !=NULL 은 하면 안됨
-- IS NULL , IS NOT NULL 사용
-- 커미션을 받지 않는 사원의 목록
SELECT first_name, commission_pct FROM employees WHERE commission_pct IS NULL;
-- 연습문제
-- 담당 매니저가 없고, 커미션을 받지 않는 사원의 목록
SELECT first_name, manager_id, commission_pct FROM employees WHERE manager_id IS NULL and commission_pct IS NULL ;
-- 집합 연산자 IN
-- 부서번호가 10, 20, 30 인 사원들의 목록
SELECT first_name , department_id FROm employees Where department_id = 10 or department_id = 20 or department_id = 30;
SELECT first_name , department_id FROM employees WHERE department_id IN (10, 20, 30);
-- ANY
SELECT first_name , department_id FROM employees WHERE department_id =ANY (10,20,30);
-- ALL : 뒤에 나오는 집합 전무 만족
select first_name, salary FROM employees WHERE salary>ALL(12000,17000);
-- LIKE 연산자 : 부분 검색
-- % : 0글자 이상의 정해지지 않은 문자열
-- 1글자 (고정) 정해지지 않은 문자
-- 이름에 am을 포함한 사원의 이름과 급여를 출력
select first_name, salary FROM employees WHERE first_name LIKE '%am%';
-- 연습
-- 이름의 두번재 글자가 a인 사원의 이름과 연봉
select first_name, salary FROM employees WHERE first_name LIKE 'a%';
-- ORDER BY : 정렬
-- 오름차순 : 작은값 -> 큰값 ASC(default)
-- 내림차순 : 큰값 -> 작은값 DESC
-- [연습] hr.employees
-- 부서 번호를 오름차순으로 정렬하고 부서번호, 급여, 이름을 출력하십시오
SELECT department_id , salary ,first_name FROM employees Order by department_id ;
-- 급여가 10000 이상인 직원의 이름을 급여 내림차순(높은 급여 -> 낮은 급여)으로 출력하십시오
SELECT first_name , salary FROM employees WHERE salary>=10000 Order by salary DESC;
-- 부서 번호, 급여, 이름 순으로 출력하되 부서번호 오름차순, 급여 내림차순으로 출력하십시오
SELECT department_id , salary ,first_name FROM employees ORDER BY department_id ASC, salary DESC;
-----------------
-- 단일행 함수
-- 한 개의 레코드를 입력으로 받는 함수
-- 문자열 단일행 함수 연습
SELECT first_name , last_name, Concat(first_name, Concat(' ',Last_name)), -- 연결
Initcap(first_name||' '||last_name), -- 각 단어의 첫글자만 대문자
LOWER(first_name), -- 모두 소문자
UPPER(first_name), -- 모두 대문자
LPAD(first_name,10,'*'), -- 왼쪽 *로 채우기
RPAD(first_name,10,'*') -- 오른쪽 * 로 채우기
from employees;
SELECT LTRIM (' ORCLE '), -- 왼쪽 공백 제거
RTRIM(' ORCLE '), -- 오른쪽 공백 제거
TRIM('*' FROM '*********DATABASE*************'),
SUBSTR('ORACLE Database',8,4), -- 부분 문자열
SUBSTR('ORACLE Database',-8,8)
FROM employees;
-- 수치형 단일행 함수
SELECT ABS (3.14), -- 절대값
CEIL (3.14), -- 소숫점 올림
FLOOR(3.14), -- 소수점 내림
MOD(7,3), -- 나머지
POWER (2,4), -- 제곱
ROUND(3.5), -- 소수점 반올림
ROUND(3.14159, 3), -- 소수점 3자리 까지 반올림 표현
TRUNC(3.5), -- 소수점 버리기
TRUNC(3.14159,3), -- 소수점 3자리까지 버림으로 표현
SIGN(-10) -- 부호 혹은 0
FROM dual;
-- -------
-- DATE FORMAT
------------
-- 현재 날짜와 시간
SELECT SYSDATE FROM dual; -- 1행
SELECT SYSDATE FROM employees; -- employees의 record갯수만큼
-- 날짜 관련 단일행 함수
SELECT SYSDATE,
ADD_MONTHS(sysdate,2), -- 2개월 후
LAST_DAY(SYSDATE), -- 이번달의 마지막 날
MONTHS_BETWEEN(SYSDATE,'99/12/31'), -- 1999년 12/31 이후 몇달이 지났는가?
NEXT_DAY(sysdate,7), -- 7일 후
ROUND(sysdate,'MONTH'),
ROUND(sysdate,'YEAR'),
TRUNC(sysdate,'MONTH'),
TRUNC(sysdate,'YEAR')
FROM dual;
-------------------
-- 변환함수
-------------------
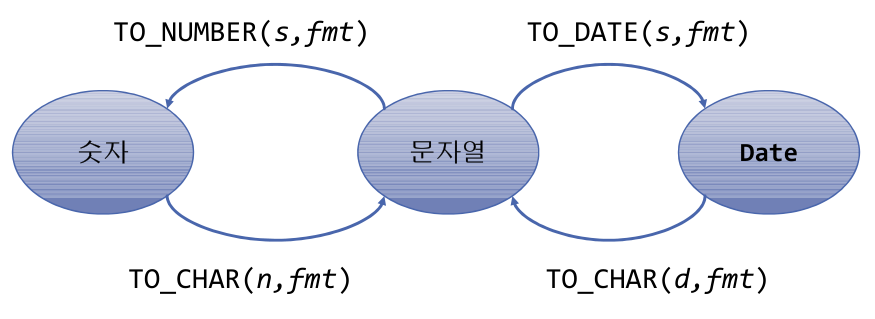
-- TO_NUMBER(s,fmt) : 문자열을 포맷에 맞게 수치형으로 변환
-- TO_DATE(S,FMT) : 문자열을 포맷에 맞게 날짜형으로 변환
-- TO_CHAR(O,FMT) : 숫자 OR 날짜를 포맷에 맞게 문자형으로 변환
-- TO_CHAR
SELECT first_name, HIRE_DATE,
TO_CHAR(hire_date,'yyyy-mm-dd'),
TO_CHAR(sysdate,'yyyy-mm-dd HH24-mi:ss')
FROM employees;
SELECT TO_CHAR(300000,'L999,999,999') FROM dual;
SELECT first_name,
To_CHAR(salary*12,'$999,999,999.99') SAL
FROM employees;
-- TO_NUMBER : 문자형 -> 숫자형
SELECT TO_NUMBER('2021'),
To_NUMBER('$1,450.13','$999,999,999.99')
FROM dual;
-- TO_DATE : 문자형 -> 날짜형
SELECT TO_DATE('1999-12-31 23-59-59','YYYY-MM-DD HH24-MI-SS')
FROM dual;
-- 날짜 연산
-- Date +(-) NUMBER : 날짜에 일수 더하기(뺴기)
-- Date - Date : 두 date 사이의 차이 일수
-- Date +(-) Number /24 : 날짜에 시간 더하기
SELECT TO_CHAR(sysdate, 'yy/MM/DD HH24:MI') 오늘날짜,
SYSDATE + 1, -- 1일 뒤
Sysdate -1, -- 1일 전
SYsdate - TO_DATE('19991231'), -- 두날 사이의 차
TO_CHAR(sysdate + 13/24 , 'YY/MM/DD HH24:MI')-- 13시간 후
FROM dual;
-------------
-- NULL 관련
-------------
SELECT first_name,
salary,
commission_pct,
salary+salary*nvl(commission_pct,0) commision
FROM employees;
SELECT first_name,
salary,
commission_pct,
nvl2(commission_pct, commission_pct*salary , 0) commission
FROM employees;
-- CASE
-- AD관련 직원에겐 20%,SA관련 직원에겐 10%, IT관련 직원에겐 8%, 나머지는 5% 지급
SELECT first_name, job_id,SUBSTR(job_id,1,2),
CASE SUBSTR(job_id,1,2) WHEN 'AD' THEN salary * 0.2
WHEN 'SA' THEN salary*0.1
WHEN 'IT' THEN salary*0.08
ELSE salary*0.05
END bonus
FROM employees;
-- DECODE 함수
SELECT first_name, job_id, salary, SUBSTR(job_id,1,2),
DECODE(SUBSTR(job_id,1,2),
'AD',salary * 0.2,
'SA',salary*0.1,
'IT',salary*0.08,
salary * 0.05)
bonus
FROM employees;
--[연습] hr.employees
-- 직원의 이름, 부서, 팀을 출력하십시오
-- 팀은 코드로 결정하며 다음과 같이 그룹 이름을 출력합니다
-- 부서 코드가 10 ~ 30이면: 'A-GROUP'
-- 부서 코드가 40 ~ 50이면: 'B-GROUP'
-- 부서 코드가 60 ~ 100이면 : 'C-GROUP'
-- 나머지 부서는 : 'REMAINDER'
SELECT first_name, department_id ,
CASE
WHEN department_id>=10 and department_id<=30 THEN 'A-GROUP'
WHEN department_id>=40 and department_id<=50 THEN 'B-GROUP'
WHEN 50<department_id and department_id<60 THEN 'C-GROUP'
ELSE 'REMAINDER'
END
FROM employees ORDER BY department_id;'DB-Oracle' 카테고리의 다른 글
| Oracle SQL - JOIN (0) | 2021.08.04 |
|---|---|
| Oracle SQL - Group & Aggregation (0) | 2021.08.04 |
| Oracle SQL - Basic Query - SELECT 문의 기초 (0) | 2021.08.03 |
| git 과 github / Git for Windows 설치 및 사용 (0) | 2021.08.02 |
| ORACLE Develoer 설치 및 Demo 세팅 (0) | 2021.08.02 |